> getallen5 <- c(3,7,18,2,5)
> (getallen5 + 2) * 3
[1] 15 27 60 12 21Denk om de haakjes!
|
In deze tutorial leer je de basics van R. Je leert vooral zaken die een randvoorwaarde zijn om goed met de software te kunnen werken; je wordt klaargestoomd om jezelf verder in de software te verdiepen, zelfstandig of m.b.v. meer geavanceerde cursussen. Als je deze tutorial hebt doorlopen, weet je hoe je moet R en RStudio moet werken, wat zogenaamde objecten zijn en hoe je deze aanmaakt en bewerkt, hoe je een script bouwt om je data-analyse vorm te geven, hoe je functies en packages gebruikt, en ben je bekend met de beginselen van het verkennen en analyseren van data. Je zult in deze tutorial een aantal dingen terug zien komen. Je gaat (programmeer)code tegenkomen, met daaronder veelal het resultaat van deze code. Je kunt deze code overtypen of kopiëren en plakken in je eigen RStudio-software. De ervaring leert dat het zelf typen van de code de materie beter doet beklijven dan kopiëren en plakken. Ook zul je af en toe een grijs vlak met een vraag langs zien komen, met twee benedenwaartse pijlen. Je kunt het antwoord op de vraag zien door éénmaal op het grijze vlak te klikken. Ten slotte vind je in de rechter kantlijn een korte omschrijving van in de tekst genoemde belangrijke begrippen. |
|
Deze tutorial kun je het beste bekijken met een browserscherm dat minimaal 1500 pixels breed is. Jouw scherm is pixels breed. Het is handig als je bij aanvang van deze tutorial al wat basale kennis over statistiek hebt. We gaan het bijvoorbeeld hebben over gemiddelden en standaarddeviaties, kwartielen en de mediaan, en we voeren t-toetsen en een chi-kwadraat-toets uit. Mocht je niet met alle begrippen bekend zijn dan is dit echter geen probleem. Misschien is het wat veel om de tutorial in één keer te doorlopen. Met de hele tutorial zul je al gauw een paar uur zoet zijn, wellicht is het na hoofdstuk 5 een mooi moment om op een volgend moment verder te gaan. De volgende keer is ’t mogelijk wel handig om kort de eerdere hoofdstukken nog een keertje door te nemen, ter opfrissing. Leren is herhalen. Gedurende de tutorial zul je programmeercode te zien krijgen die je kunt overnemen. Schroom niet om hierin af en toe off-piste te gaan en te experimenteren door dingen te veranderen. Je zult zo af en toe onderlijnde woorden tegenkomen. Als je hier met je muis overheen gaat, of als je erop drukt als je een tablet/telefoon gebruikt, krijg je een verduidelijking of herhaling van het onderwerpTer illustratie. te zien. |
|
Je gebruikt deze tutorial waarschijnlijk omdat je R wilt leren gebruiken. Nu is het zo dat de standaard software voor R nogal aftands en gebruiksonvriendelijk is. Gelukkig is er RStudio, dit is een IDE om R heen. Zie RStudio als een mooie schil om een wat ontoegankelijker stukje software heen. R en RStudio zijn dus twee aparte programma’s, waarbij het laatste programma het eerste programma als het ware in zich opneemt. Er zijn meerdere IDE’s voor R (bijv. RCommander, Jupyter Notebook, Tinn-R), maar RStudio is verreweg het populairst. In onze tutorials zullen we de namen R en RStudio door elkaar gebruiken. Hierbij is het zo dat, waar RStudio genoemd wordt, het om iets in de IDE gaat (bijv., het bekijken van plots, het klikken op een knop). Waar R genoemd wordt, gaat het meer om de code die je geschreven hebt, en eventueel wat er zich “onder de motorkap” afspeelt. R en RStudio zijn allebei gratis, je kunt ze vinden via je favoriete zoekmachine en op elk zinnig besturingssysteem installeren. |
|
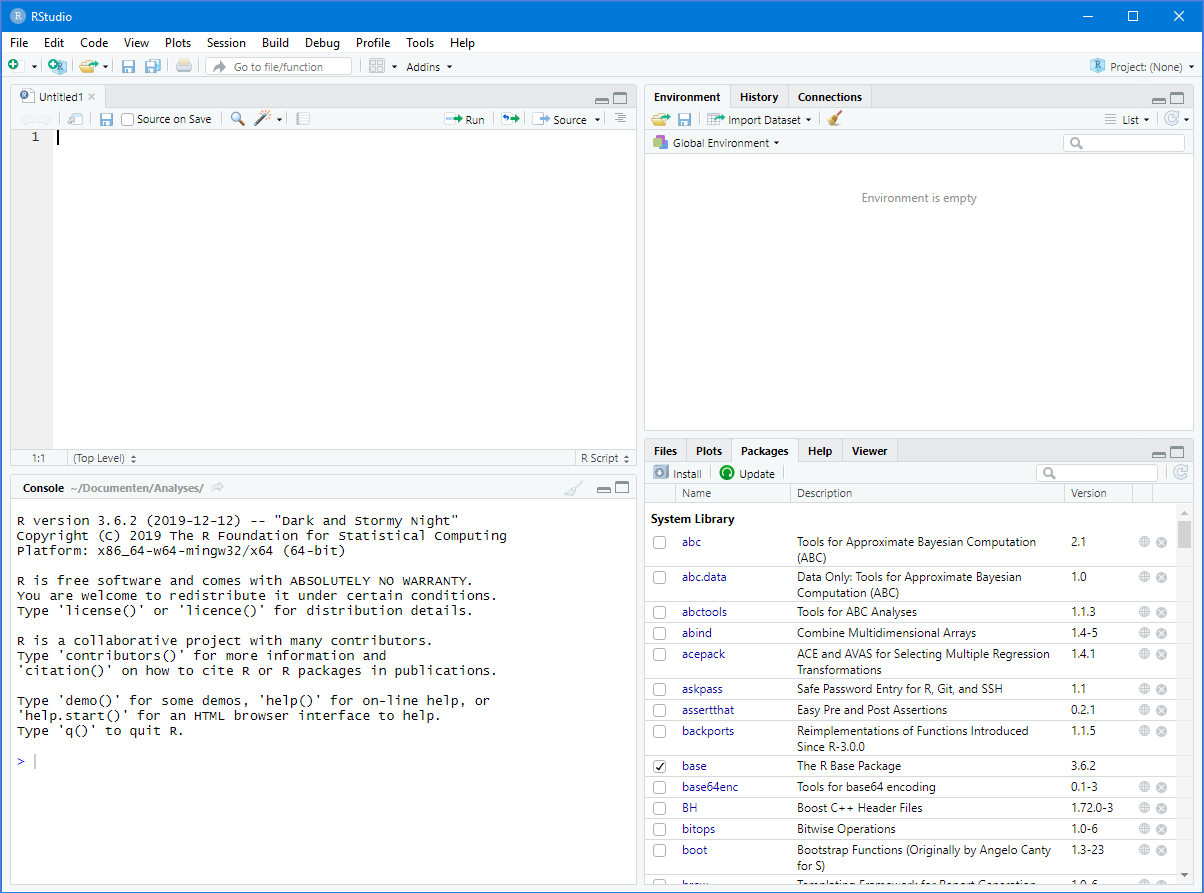
Als je RStudio voor het eerst opent, ziet je scherm er ongeveer zo uit:
We zien links een paneel met daarin de console, en rechts twee panelen met elk verschillende tabbladen. |
|
In de console zie je de daadwerkelijke R-sessie. Zou je geen RStudio gebruiken, maar het basale R, dan zou dit het scherm zijn dat je ziet. Je ziet hier een cursor, waar je een commando kunt intypen. Typ je bijvoorbeeld |
In de console wordt je R-code uitgevoerd. |
|
|
Dit is meteen een voorbeeld van wat je in deze tutorial veel gaat tegenkomen: in een grijs vlak valt een stukje code te zien, met daaronder de uitkomst daarvan. De uitkomst Je hebt zojuist je eerste functie gebruikt, de functie |
|
In de praktijk zul je niet vaak op een directe manier met het console interacteren. Meestal zul je dit doen vanuit een R-script in de source editor. Om een nieuw R-script te maken, ga je in RStudio naar File -> New File -> R Script. Je scherm ziet er dan ongeveer als volgt uit:
In een script kun je het hele verloop van je data-analyseproject uiteenzetten. Denk hierbij aan het inladen van data, het bewerken ervan, de data-analyse en het eventueel comprimeren van de resultaten van je analyses. Een mooi uitgangspunt hierbij is dat je je script in 1 keer zou moeten kunnen runnen, telkens weer, en dat er telkens hetzelfde uit komt. We gaan de editor later in deze tutorial uitgebreid gebruiken. Mocht je bekend zijn met het gebruik van syntaxen in SPSS, of van do-bestanden in Stata: het bouwen van een R-script is hiermee vergelijkbaar. |
|
In het paneel rechtsboven zie je drie tabbladen: Environment, History en Connections. In Environment zie je een overzicht van je workspace: variabelen die je hebt aangemaakt, datasets die je hebt geopend, functies die je hebt geschreven of anderszins ingeladen. Gaandeweg de tutorial zul je hier van alles in zien verschijnen. Het tabblad History bevat een overzicht van al je laatst gebruikte commando’s. Vanuit dit tabblad kun je eerder gebruikte commando’s naar de console transporteren (om meteen uit te voeren), of naar je editor laten verplaatsen, om het op te nemen in een script dat je aan het schrijven bent. Het tabblad Connections laten we even voor wat het is. In de praktijk zul je merken dat je vooral het tabblad Environment zult gebruiken. |
Het tabblad Environment geeft een weergave van je workspace. |
|
Het paneel rechtsonder bevat vijf tabbladen. Dit zijn Files, Plots, Packages, Help en Viewer. In Files kun je door je bestanden bladeren, en bijv. R-scripts openen. In Plots krijg je grafieken te zien die je R hebt laten tekenen. Onder Packages kun je zgn. packages installeren en inladen. Packages zijn extra bundels met functionaliteit die door derden zijn geschreven. Op de CRAN website kun je meer informatie vinden over packages. We gaan hier later verder op in. Verder is er nog het tabblad Help, waarin je meer info kunt krijgen over functies in R. Er is ook nog het tabblad Viewer, dat wordt vooral gebruikt om webcontent te bekijken die je genereert met iets wat RMarkdown heet. Zo is deze hele tutorial bijvoorbeeld met RMarkdown geschreven, dus in RStudio. Dit laat zien dat je met R niet alleen data-analyses kunt doen en handige functionaliteit kunt programmeren om op een efficiënte manier je data te lijf te gaan; je kunt ook integraal de resultaten van je analyses verwerken in bijvoorbeeld een verslag. We gaan in deze tutorial niet op het gebruik van RMarkdown in. |
|
R is een zgn. object-georiënteerde programmeertaal. Dit betekent dat je werkt met objecten die je maakt. Een heel simpel voorbeeld is de volgende code die je in de console kunt uitvoeren: Dit betekent zoiets als “maak een variabele genaamd Nu we het object Of, iets erbij optellen, en dat in een nieuw object opslaan: Ook b zie je nu staan in je Environment. Door |
|
In bovenstaand voorbeeld hebben we een enkele waarde toegekend aan onze aangemaakte objecten. Meestal houden we ons echter bezig met een veelvoud aan getallen, we hebben immers data van meerdere personen. Sterker nog, van elk van deze personen hebben we een scala aan gegevens. Voor we met volledige datasets aan de gang gaan, is het goed om te weten hoe je met een verzameling getallen kunt werken. Een ééndimensionale rij getallen noemen we een vector. Voor R is een variabele met één waarde, zoals in bovenstaand voorbeeld, overigens een vector met lengte 1 (er zit maar één waarde in). |
Om een vector met meer waardes te maken, gebruiken we de functie c() (wat staat voor combine). Typ in het console het volgende in:
|
||
|
Een vector is een rij met getallen, aaneengekoppeld met |
|
|
Er is een vector aangemaakt met lengte 6 (er zitten zes waarden in). Tellen we bij deze vector een getal op, dan zien we het volgende: Bij elk van de getallen wordt de waarde 3 opgeteld en je krijgt de uitkomst te zien. Dit wordt verder niet opgeslagen, we zien immers geen Je ziet dat we een nieuw object aanmaken, genaamd Merk op dat Je moet er misschien even naar turen, maar hier gebeurt het volgende: de getallen uit de kleinere vector ( Denk om de haakjes! |
|
Stel, we willen uit Het vierde element (we zien dat dit de waarde 8 is) kunnen we als volgt uit deze vector halen: Binnen de blokhaken geven we het volgnummer aan. |
|
Zoals we hierboven bespraken, is een vector een rij met waarden. Een matrix bevat ook gegevens, maar dan in meerdere rijen en kolommen. Je zou een matrix kunnen zien als de tweedimensionale broer van een vector. Als je eenmaal met “echte data” aan de slag gaat, zul je vooral met |
|
In het volgende voorbeeld maken we een kleine matrix We gebruiken hiervoor de functie Je zou hier al een heel kleine dataset in kunnen herkennen: een kolom met persoonsnummers (1 t/m 6), dan een kolom met een continue variabele (34, 27, 46, etc.), en een kolom met een zogenaamde dichotome variabele (0 en 1). |
|
In de praktijk zal het niet zo vaak (eigenlijk: nooit) voorkomen dat je een volledige dataset maakt op de manier van het bovenstaande voorbeeld. Wat wel eens kan gebeuren, is dat je een matrix samenstelt uit meerdere vectoren. Stel, je hebt de vectoren Dan kunnen we dezelfde Je ziet dat het resultaat hetzelfde is, alleen heeft |
|
Bij de vector zagen we dat we informatie konden extraheren door een getal tussen blokhaken achter de variabelenaam te plaatsen. Bij de matrix is dit niet voldoende: we moeten een rijnummer en een kolomnummer opgeven. Stel, we willen uit de derde rij de informatie uit de tweede kolom hebben (dit is het getal 46). Dan kunnen we dit als volgt doen: Nu geven we tussen de blokhaken het rijnummer en het kolomnummer op. Altijd eerst het rijnummer, dan het kolomnummer. Wil je een complete rij opvragen, dan kan dat op de volgende manier: Je specificeert voor de komma het rijnummer, en na de komma niets. En een volledige kolom doe je dus als volgt: Je definieert geen rijnummer, alleen een kolomnummer (ná de komma). De tweede en derde rij krijg je als volgt: De eerste en derde kolom krijg je als volgt: |
|
Naast het werken met kwantitatieve data kun je in R ook met tekstdata werken. We gaan in deze tutorial niet in op het analyseren van tekstdata, maar willen wel even stil staan bij dit type gegevens. Tekstdata worden in R (zoals eigenlijk in alle programmeertalen) in aanhalingstekens ingesloten. Het maakt hierbij niet uit of je enkele of dubbele aanhalingstekens gebruikt, zolang je maar hetzelfde type aanhalingsteken gebruikt om een stuk tekst heen. Voer in de console maar eens de volgende code uit: De aanhalingsteken hebben een belangrijke functie. R verwacht namelijk op enig moment in de console een getal (bijv. dan krijg je een foutmelding. R leest je code namelijk net als een mens: regel voor regel, en elke regel van links naar rechts. Als R Het is belangrijk om te weten dat R (zoals elke programmeertaal) hier heel strikt in is. Als je data importeert, wil het nog wel eens voorkomen dat een variabele waarvan je denkt dat het een numerieke variabele is, als tekstvariabele wordt gezien. Bijvoorbeeld: je wilt het gemiddelde berekenen van de variabele age, waarvan je zou denken dat het een numerieke variabele is (een vector met alleen maar getallen). Dan blijkt vervolgens dat iemand van 37 jaar als leeftijd heeft staan “bijna 38!”. Dit is geen getal, maar tekst. En om deze reden wordt de hele variabele als tekstvariabele gezien. En daar kun je niet mee rekenen, je krijgt dan een foutmelding. Kijk maar (we gebruiken de functie In je Environment zie je dan ook, dat naast numerieke vectoren |
|
Tot nu toe hebben we het gehad over vectoren, matrices en karakters als objecten. Dit soort objecten zijn de zogenaamde data types. Andere vormen van data types zijn data frames, lists, factors en arrays. Hiernaast zijn er nog andere soorten objecten in R, zoals functies, en de uitkomsten van een analyse. Een object kun je zien als “iets dat in het geheugen is geladen en waar je bewerkingen op of mee kunt doen.” Klinkt misschien nog wat vaag, maar gaandeweg deze tutorial gaan we er meer tegenkomen. |
|
Je weet inmiddels dat we in R met objecten werken. Objecten hebben namen, en elke keer als je zo’n object wilt benaderen, moet je die naam intypen. Dat wordt natuurlijk best vervelend na een tijdje, zeker als de namen wat langer zijn. Gelukkig is daar tab completion. Stel, je wilt 
|
Met tab completion typ je je code sneller, doordat R je tekstsuggesties doet wat betreft o.a. functies en objectnamen. |
|
|
Tot nu toe hebben we gewerkt vanuit de console. Eerder werd al genoemd dat je dit in de praktijk niet zoveel zult doen, maar vanuit een R-script zult werken. Hoog tijd om de daad bij het woord te voegen, en de editor eens te verkennen. |
In R zul je meestal met een script werken. |
|
|
Je kunt in de editor meerdere commando’s tegelijk selecteren, en bovenaan op Run klikken, of op De code wordt regel voor regel in de console uitgevoerd, waar je ook de output te zien krijgt. In het vervolg geven we de in- en output als volgt weer: Klein verschil met voorgaande output: vanaf nu maken we gebruik van de standaard code highlighting in de editor. En laten we eventuele prints (zoals |
||
Ook handig: in je script kun je commentaarregels (comments) opnemen, om je code te verduidelijken. Dit doe je met een hekje (#). Probeer bijvoorbeeld eens het volgende script in zijn geheel te runnen (het promptkarakter > is voor het gemak weer even weggehaald, zo kun je het geheel makkelijk copypasten):
|
Met een |
|
Als je de regel met het commentaar selecteert en runt, dan snapt R dat hij deze regel niet moet interpreteren - je krijgt dus geen melding dat hij variabelen niet kan vinden o.i.d., zoals we hierboven in het voorbeeld met variabele Je kunt je script opslaan via File -> Save / Save as…. Hij krijgt de bestandsextensie .R. Een laatste opmerking over het gebruik van scripts, voor nu. Vaak werk je met externe databestanden en schrijf je dingen weg naar bestanden (denk aan grafiekjes en nieuwe datasets). Het is dan van belang om R te laten weten in welke map je bezig bent. Meestal ligt het voor de hand om je R-script in dezelfde map te hebben als je databestand. De map waarin je aan het werk bent, heet je working directory. Je huidige working directory kun je opvragen met de functie |
We hebben al een aantal functies gezien: print(), c(), cbind(), matrix() en mean(). Zojuist zagen we ook nog getwd() en setwd(). Een functie is een object dat een commando, of een reeks commando’s, voor je uitvoert. Vaak is het zo dat je er iets (bijvoorbeeld een vector) “in stopt”, en dat je er dan een bewerking van terugkrijgt. In de functie mean() kun je bijvoorbeeld een vector stoppen, en je krijgt er de gemiddelde waarde van die vector voor terug. Je kunt je voorstellen dat dit sneller is dan zelf in R alle elementen van een vector bij elkaar op te tellen, en het resultaat te delen door het aantal elementen.
|
Een functie voert een reeks commando’s voor je uit. |
|
|
Een functie kun je herkennen aan de haakjes die direct op de functienaam volgen. Tussen deze haakjes kun je een en ander specificeren voor het uitvoeren van de functie. Laten we kijken wat er zoal te ontdekken valt over het gebruik van functies. We maken twee variabelen aan, om het gebruik van functies te illustreren. Dit hebben we eerder gezien, we gebruiken hiervoor Bij de functie Merk op dat we de variabele
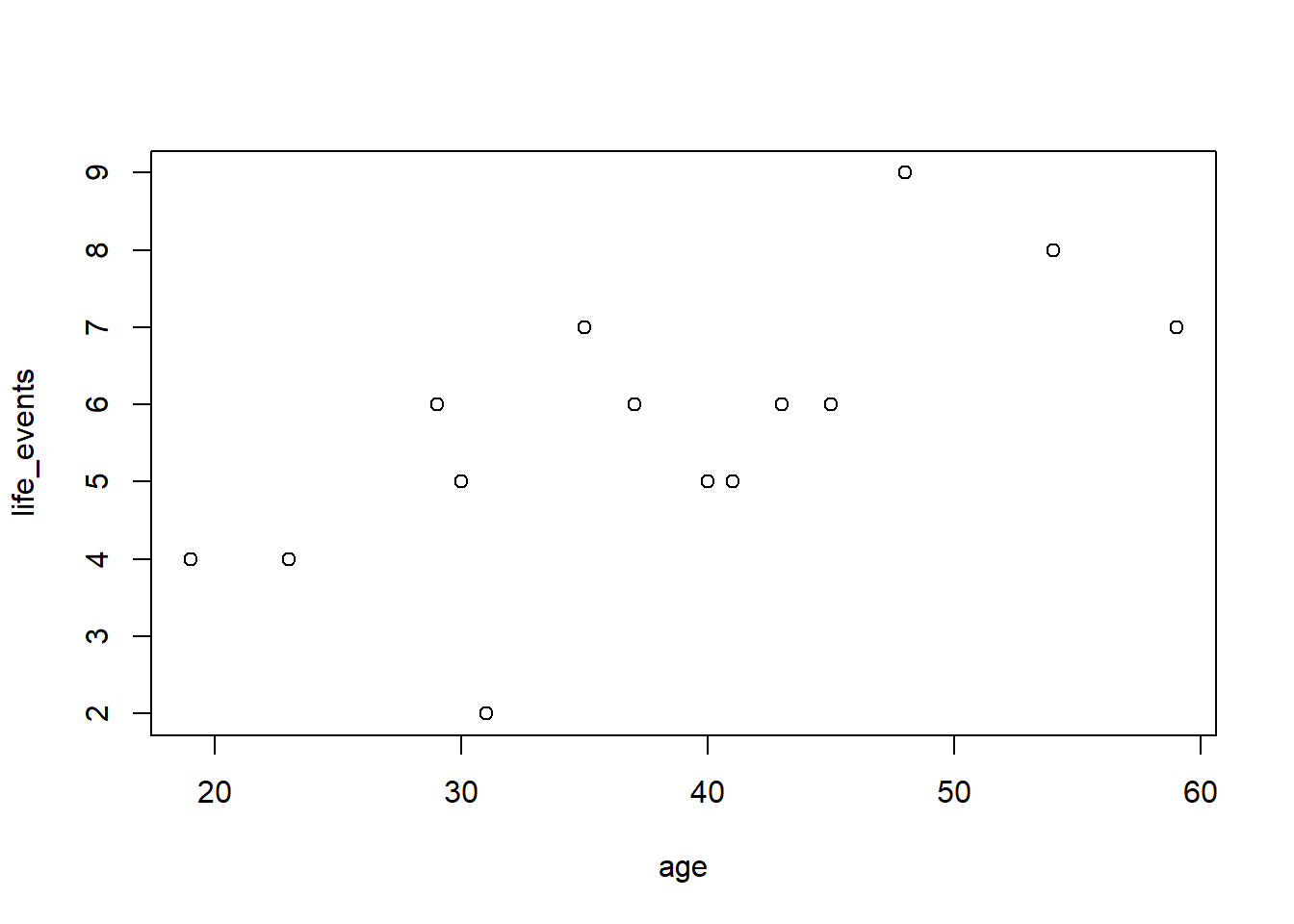
We zien dat de twee variabelen tegen elkaar afgezet worden in een grafiek. Blijkbaar is dit wat |
||
|
Je ziet dat in het vak rechtsonder het tabblad Help actief worden, waarin de documentatie (de handleiding) van de
|
Een functie heeft argumenten waarmee je opties kunt ingeven. |
|
|
Als we in de documentatie doorklikken naar graphical parameters, zien we dat we eigenschappen van de grafiek kunnen veranderen zoals plotkleur (
Soms wordt uit de documentatie niet direct duidelijk wat er nou bedoeld wordt met de verschillende argumenten. Vaak is de sectie Examples onderin de helpfile dan inzichtgevend. En mocht ’t dan nog niet duidelijk zijn: Google is your friend. Wat misschien opvalt, is de manier waarop Een laatste ding wat opvalt aan bovenstaande code, we noemden het al, is dat ’ie over twee regels is verdeeld. Dit kun je doen als een coderegel naar je gevoel wat te lang wordt. De witte ruimte tussen het begin van de regel en Let bij het gebruik van meerdere regels wel op dat je geen komma’s, aanhalingstekens of haakjes-sluiten vergeet! We kunnen ook het gemiddelde aantal life-events berekenen. Hiervoor gebruiken we - dit weten we al - de functie Als je de documentatie van Je kunt tab completion ook gebruiken voor functienamen. Voor de functie 
Stel, dat we het gemiddelde willen afronden op drie decimalen, dan doen we het volgende: De logica is hier: je wilt een afgerond gemiddelde hebben; hiervoor bereken je eerst het gemiddelde (de binnenste functie), en daarna rond je de uitkomst hiervan af (de buitenste functie,
|
|
Bij het gebruiken van functies zul je ongetwijfeld fouten maken. Zelfs de meest doorgewinterde R-programmeur maakt dagelijks fouten bij het gebruiken van functies. Een aantal fouten die je zult tegenkomen: |
|
Soms vraag je van R om een argument op een functie toe te passen, dat niet bestaat. Soms gebeurt dit omdat je een typfout hebt gemaakt, soms omdat je denkt dat het argument bestaat, maar dat is dan kennelijk niet zo. Probeer de volgende voorbeelden maar eens: In allebei de gevallen gaat het om een typfout. Het komt ook weleens voor dat je denkt dat een argument bestaat voor een functie, maar dat is dan niet zo (je verwart hem met een andere functie). Kijk dan in de helpfile van een functie om te achterhalen wat er mis gaat. |
|
Zoals we eerder zagen, staat tekst tussen aanhalingstekens. Zorg ervoor dat voor elk aanhalingsteken dat je gebruikt om die aanduiding van een stukje tekst te openen, ook een aanhalingsteken aanwezig is om hem te sluiten. RStudio helpt je hierbij, door voor ieder aanhalingsteken dat je typt, meteen alvast een tweede neer te zetten, maar soms gaat dit toch nog fout. Probeer dit maar eens: We zijn het aanhalingsteken na |
|
Een beetje hetzelfde als de fout met de aanhalingstekens, maar met een andere uitkomst. Voor elk haakje-openen moet er een haakje-sluiten zijn. Zolang deze er niet staat, blijft R op de afronding van je commando wachten. Probeer dit maar eens: We zijn het haakje-sluiten aan het einde van de functie vergeten, waardoor R denkt dat je misschien nog meer wilt specificeren. Als je naar de console kijkt, zie je dat er aan het begin van de regel niet een |
|
Bij het “nesten” van functies kan het zo zijn dat een haakje op een verkeerde plek komt te staan. Dit levert niet altijd een foutmelding op! Kijk hier eens naar: Het haakje-sluiten voor de |
| Een groot pluspunt van R is dat er online een gigantische community is van gebruikers die actief bezig zijn de functionaliteit te verbeteren en uit te breiden, en die hier blogs, plogs en vlogs over maken. Gewoonlijk is deze functionaliteit beschikbaar in de vorm van packages. R kan uit zichzelf al veel, en er worden ook al best wat packages standaard geïnstalleerd, maar toch zijn er altijd wel dingen te verzinnen die je wilt doen, die niet standaard in R zitten. Eerder noemden we al de website van R, CRAN, waar packages te vinden zijn. |
M.b.v. packages breid je de functionaliteit van R uit. |
|
|
Je kunt packages op twee manieren installeren. De meest omslachtige manier is om ze van CRAN te downloaden als zipbestand of tarball, en ze via het tabblad Packages, d.m.v. de knop Install te installeren. Veel handiger is de standaardoptie, om ze (onder dezelfde knop) direct uit de CRAN repository te downloaden - je hebt hier uiteraard een internetverbinding voor nodig. De omslachtige optie gebruik je bijvoorbeeld als je een oudere versie van een package nodig hebt. Rechtstreeks vanuit de CRAN repository wordt altijd de nieuwste versie geïnstalleerd. Als je een package geinstalleerd hebt, kun je hem inladen met het de functie In het scherm Packages zie je het package nu met een vinkje ervoor staan. We kunnen functies die in dit package zitten, nu gebruiken. In dit specifieke geval gaat het om functies waarmee je data kunt importeren uit een aantal statistiekprogramma’s, zoals SPSS, Stata, SAS en Minitab (eigenlijk allemaal software die je niet meer zou moeten willen gebruiken als je eenmaal wat kundiger bent in R 😉). |
|
Als het je is gelukt om dit punt in de tutorial te bereiken, dan ben je klaar voor het echte werk: het is tijd om met een volledig databestand aan de slag te gaan. |
|
Download het volgende bestand: Databestand FDL.sav. Dit is een SPSS-databestand met daarin data die verzameld zijn met de Fictieve Depressie Lijst (de FDL). Zoals de naam al doet vermoeden, gaat het hier om verzonnen data. We hebben (zogenaamd) 100 mensen met een depressie gerandomiseerd in de groepen Dit bestand kunnen we openen met de functie |
||
|
Zoals je ziet, laden we het package op de eerste regel. Op de tweede regel gebeurt iets geks: je ziet het |
Code die je (tijdelijk) niet wilt uitvoeren, kun je met |
|
|
Op de derde regel wordt het databestand ingelezen met de |
|
Natuurlijk wil je ook data kunnen inlezen uit andere bestanden dan SPSS-bestanden. Bijvoorbeeld Excelbestanden, tekstbestanden of comma separated files. Voor de laatste twee is er standaard functionaliteit in R aanwezig: tekstbestanden kun je inlezen met Voor het lezen van Excel-bestanden kun je gebruikmaken van de packages |
|
Als het goed is, is FDL in je Environment komen te staan, onder het kopje Data. Klik je op het driehoekje ervoor, dan krijg je de variabelen te zien, en nog wat zgn. attributen (die behandelen we niet). Je ziet dat er twee typen variabelen in voorkomen: numerieke ( |
||
|
Met |
|
|
Je ziet dat er tellingen worden gedaan voor categorische variabelen, en dat voor numerieke variabelen de kwartielen, het gemiddelde en de mediaan (dit is het tweede kwartiel) worden gegeven. Voor het verkennen van individuele variabelen zou je de volgende functies kunnen gebruiken: |
||
|
We zien hier iets nieuws. De variabelenaam wordt voorafgegaan door |
Met |
|
|
Ook hier is tab completion handig: als je intypt Om een idee te krijgen van je dataset, kun je de Je kunt ook de complete dataset in een apart tabblad te zien krijgen. In het vak Environment kun je dit doen door op het half-doorzichtige rastertje rechts te klikken (op de regel met de objectnaam). Je kunt ook het volgende commando gebruiken: We kunnen ook alle waarden van een specifieke variabele opvragen. Dit doen we door bijvoorbeeld in te geven: Dit zijn alle waarden in onze dataset voor We maken een kruistabel van Er zitten 16 mannen in de CGT-interventiegroep. |
|
Zoals je in Environment kunt zien, bestaat onze dataset uit 100 observaties (rijen) van 10 variabelen (kolommen). We zeggen ook wel dat de dimensies van onze dataset 100 en 10 zijn. We kunnen dit verifiëren door de Stel, we willen specifiek van de zevende rij, de waarde in de vierde kolom (de variabele In beide gevallen gebruiken we blokhaken. De eerste manier zagen we al eerder, toen we het over matrices hadden. Op de tweede regel pakken we het iets anders aan. We willen een waarde uit een specifieke vector vissen. Een vector is ééndimensionaal, dus hoeven we maar één waarde op te geven; we willen de zevende observatie van We kunnen tussen blokhaken ook een voorwaarde zetten. Stel, we willen de leeftijden hebben, maar wel alleen van de mannen: De logica hierachter is in te zien, als we net als bij geneste functies van binnen naar buiten werken. Eerst kunnen we ons afvragen: voor welke observaties in Daar waar hier de waarde Merk op dat we hier een dubbel is-gelijk-teken ( Je zou kunnen denken dat je dit doet met Strikt genomen is dit niet juist. Hiermee krijg je de leeftijden van de vrouwen. Het kan ook zo zijn dat er bijvoorbeeld de waarde “anders” is; juist met een variabele als geslacht kan deze situatie zich voordoen, zonder dat je daar direct aan denkt. Beter is de volgende code: In het geval van onze data komt er hetzelfde uit, maar in principe is de tweede manier de juiste. Stel, je wilt de gemiddelde leeftijd van mannen weten, dan stop je om bovenstaande commando in de Het komt regelmatig voor dat er waardes missen in je dataset. Deze fictieve dataset is compleet, dus we gaan er even een missende waarde in stoppen: We veranderen de waarde op de zevende rij, vierde kolom in Die kan niet berekend worden, omdat er nu een missende waarde in zit (doe nog maar eens We zetten de oorspronkelijke waarde weer even terug: Je moet hier aan twee voorwaarden voldoen: iemand moet man zijn én in de CGT-groep zitten. Dit doe je als volgt: De crux zit ’m in Je moet hier aan één van twee voorwaarden voldoen: iemand moet óf in SES-klasse “laag”, óf in SES-klasse "gemiddeld zitten. Dit doe je als volgt: Hier zit het ’m in |
| Inmiddels ben je aardig op de hoogte van hoe je in R je data kunt inlezen en verkennen, hoe je met objecten kunt werken, en hoe je in RStudio met een script kunt werken. Tijd voor het echte werk: we gaan wat statistische analyses doen. |
|
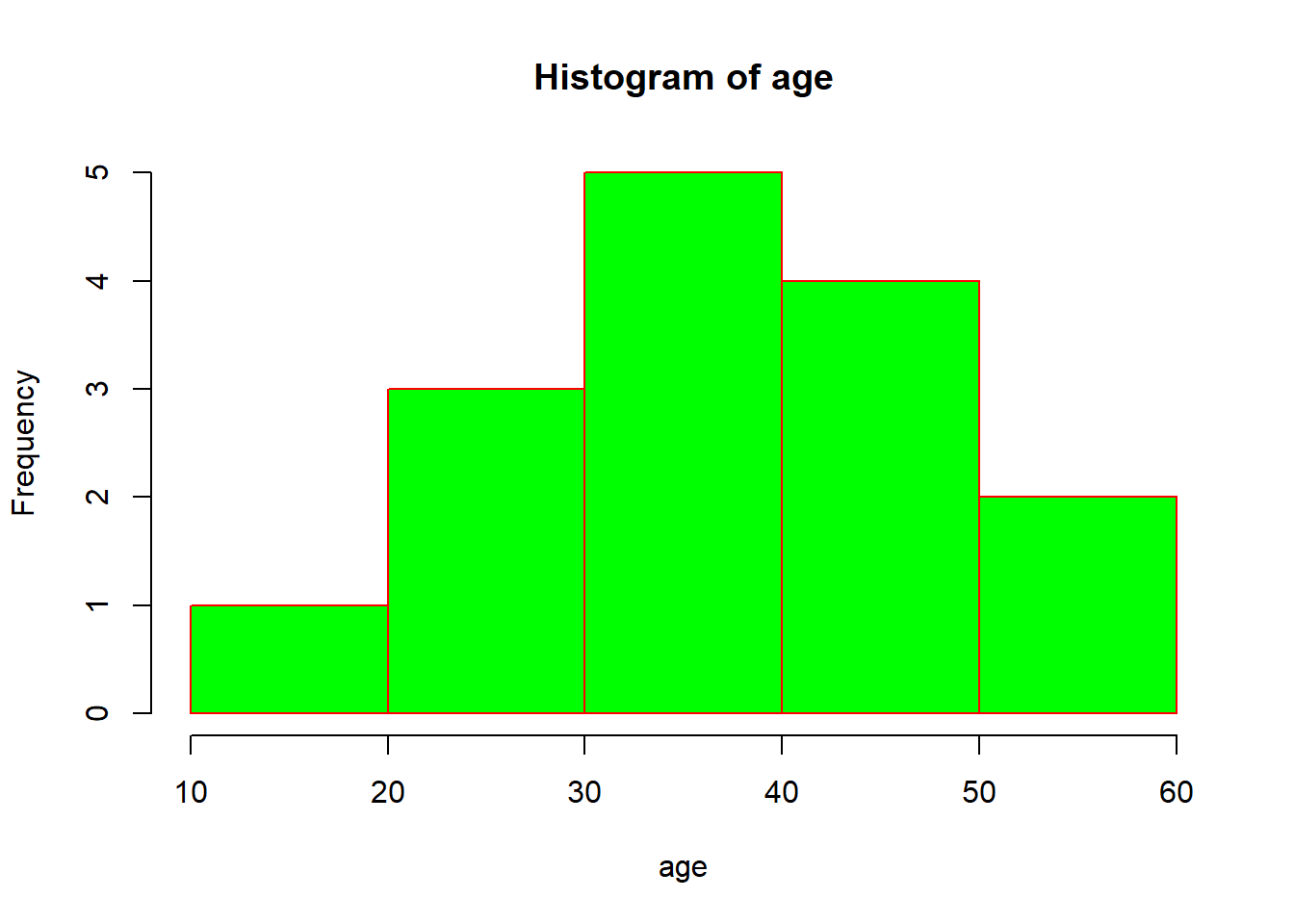
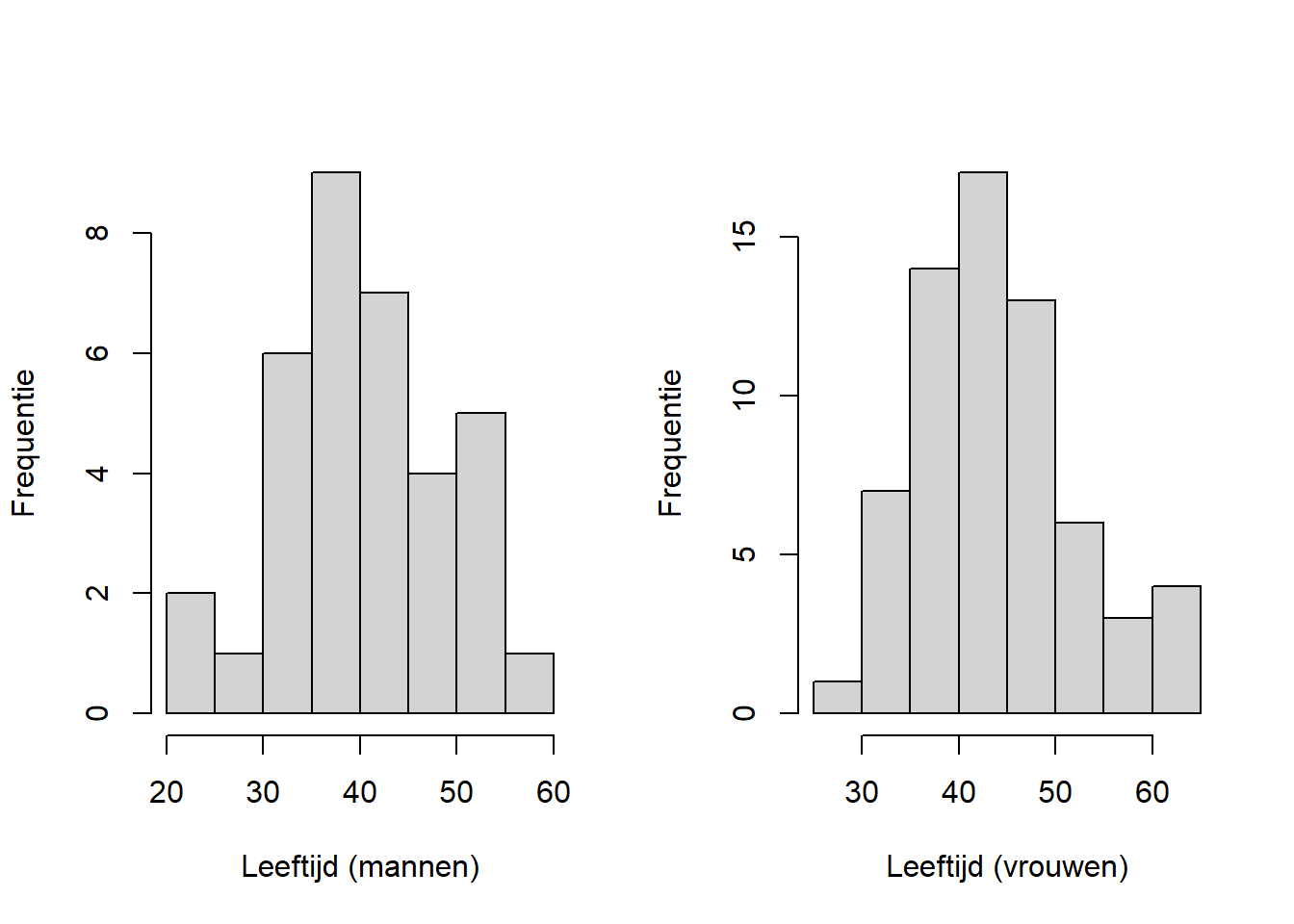
Eerder hebben we in onze dataset gekeken wat de gemiddelde leeftijd is van de mannen en van de vrouwen. Stel dat we willen toetsen of deze twee groepen statistisch significant van elkaar verschillen. Hiervoor kunnen we, mits deze variabele voor allebei de groepen normaal verdeeld is, een onafhankelijke t-toets doen. We gaan eerst eens kijken naar de normaliteit van de variabele leeftijd, zowel voor de mannen als voor de vrouwen. Om te beginnen, maken we voor de mannen en voor de vrouwen een histogram:
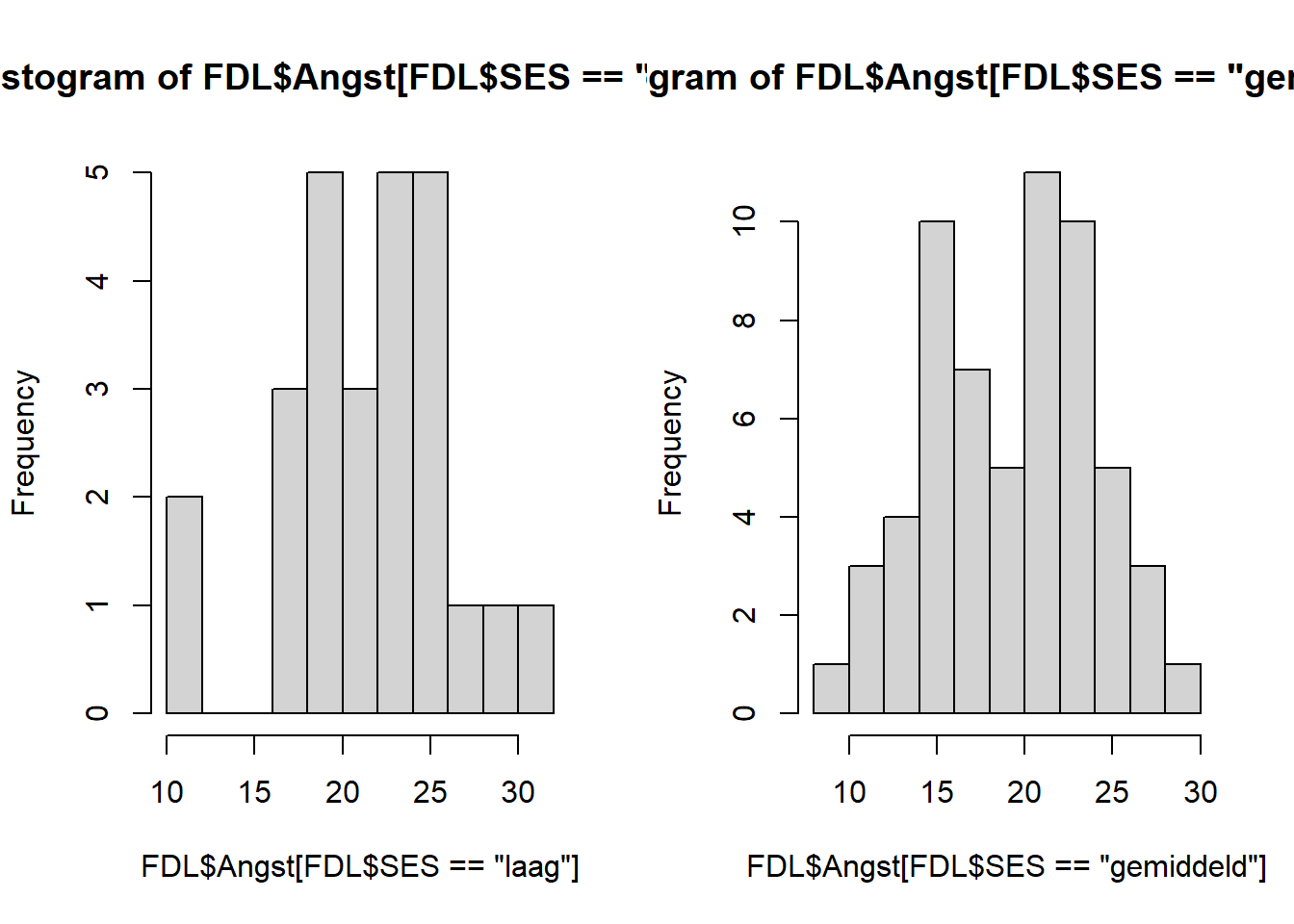
Eerst wordt er een zogenaamde grafische parameter ingesteld: met Vervolgens worden er twee histogrammen getekend. De extra argumenten die we hier meegeven en die je extra kunt specificeren, kun je natuurlijk opzoeken met Stel dat we tevreden zijn over de normaliteit bij elk van de groepen, dan kunnen we de onafhankelijke t-toets uitvoeren. Onze input bestaat uit twee vectoren: de leeftijden van de mannen ( We kunnen de onafhankelijke t-toets ook doen door niet Misschien is de derde optie het elegantst: er zit geen herhaling in wat betreft Terug naar het resultaat. We zien dat er een t-test wordt uitgevoerd met een zogenaamde Welch-correctie. Een Welch Two Sample t-test. Deze pas je toe als je er niet van uit gaat dat de varianties in beide groepen gelijk zijn (als de spreiding ongelijk is). Deze toets levert ons een t-waarde op van -2.11, wat met 68.41 vrijheidsgraden een p-waarde van 0.04 oplevert. Omdat de p-waarde hier kleiner is dan 0.05, concluderen we hier dat de mannen en vrouwen statistisch significant verschillen in leeftijd. Verder wordt er een betrouwbaarheidsinterval van het verschil gegeven, en zien we de gemiddelden van de groepen terug. We maken eerst twee histogrammen voor de angst-schaal: voor elke groep eentje. We zetten ze naast elkaar d.m.v.
De groepen zijn niet significant verschillend in hun mate van angst (p = 0.07). Een andere, misschien wel elegantere, manier is: We hanteren hier de formule-vorm, en geven in data aan dat we |
|
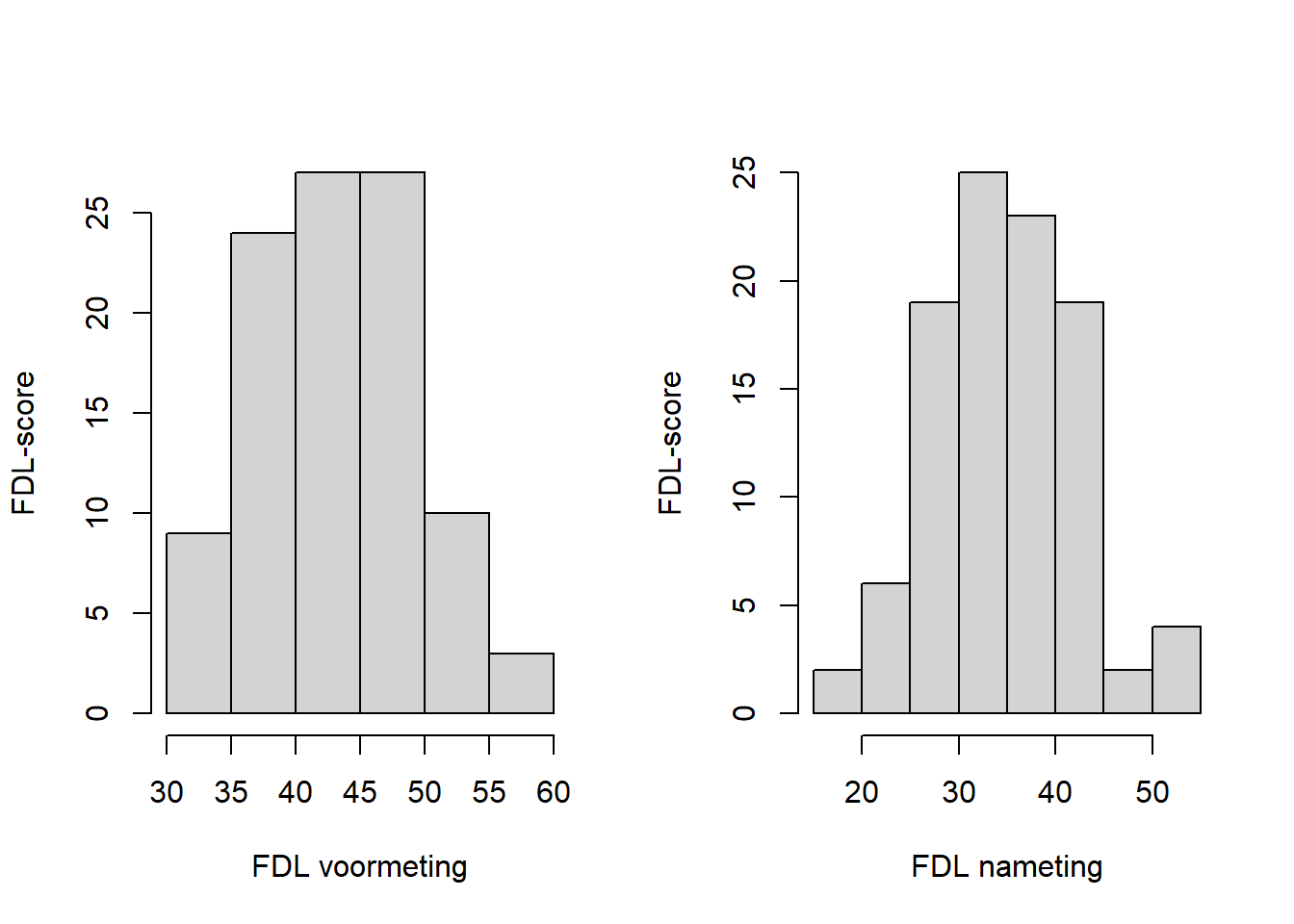
Stel, we willen weten of er een verschil is tussen de voor- en de nameting van de FDL. Ook dan kijken we eerst naar de normaliteit rond beide gemiddelden:
Vervolgens, als we tevreden zijn, voeren we de gepaarde t-toets uit Wederom geven we twee vectoren in: de voormeting en de nameting. Met het argument We kunnen hier niet met de formule-vorm werken zoals bij de onafhankelijke t-toets, en we kunnen de invoer ook niet vereenvoudigen met een data-argument (die werkt alleen bij de formule-variant, dus alleen bij de onafhankelijke t-toets). We kunnen eventueel wel het volgende doen: We stoppen de hele |
|
Stel, we willen weten of onze interventiegroepen verschillen in de man-vrouw-ratio. Hiervoor kunnen we een chi-kwadraattoets doen. Om deze te doen, moeten we eerst een kruistabel maken, zoals we hierboven al bij een opdracht gedaan hebben. Daarna volgt de chi-kwadraattoets. Vanuit de variabele |
|
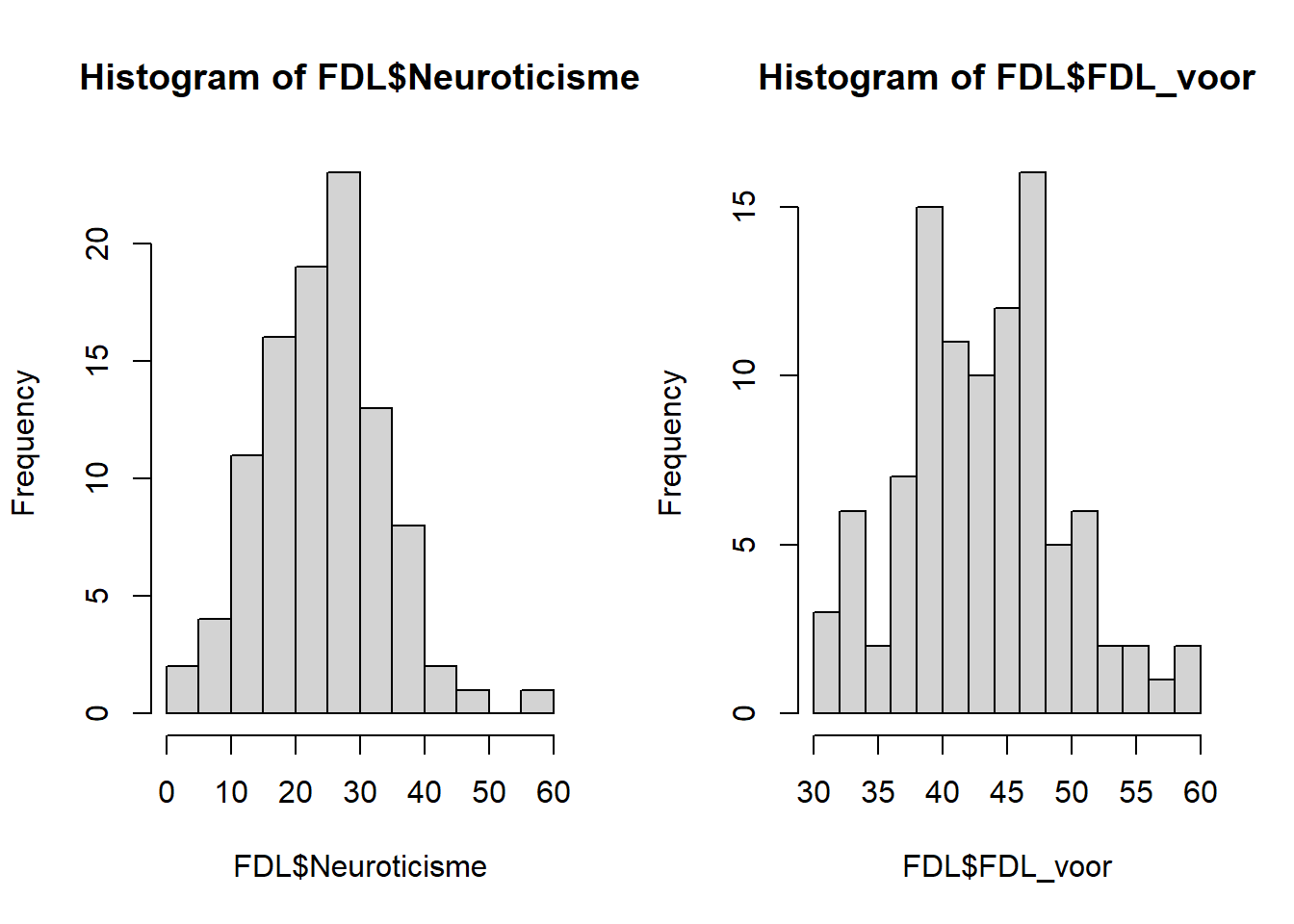
Als we de samenhang tussen twee continue variabelen willen onderzoeken, kunnen we een correlatietoets doen. Zijn beide variabelen in je vraag ongeveer normaal verdeeld, dan kunnen we een Pearson-correlatie berekenen, en als één van beide of allebei de variabelen niet normaal verdeeld zijn, kunnen we een Spearman rangcorrelatie berekenen als zogenaamd “nonparametrisch alternatief”. Voor het eerste voorbeeld berekenen en toetsen we de correlatie tussen neuroticisme en de FDL-score bij de voormeting. Eerst gaan we eens kijken hoe ’t zit met de verdeling van beide variabelen.
De samenhang is niet heel groot (r = 0.22), maar wel statistisch significant (p = 0.03). Voor
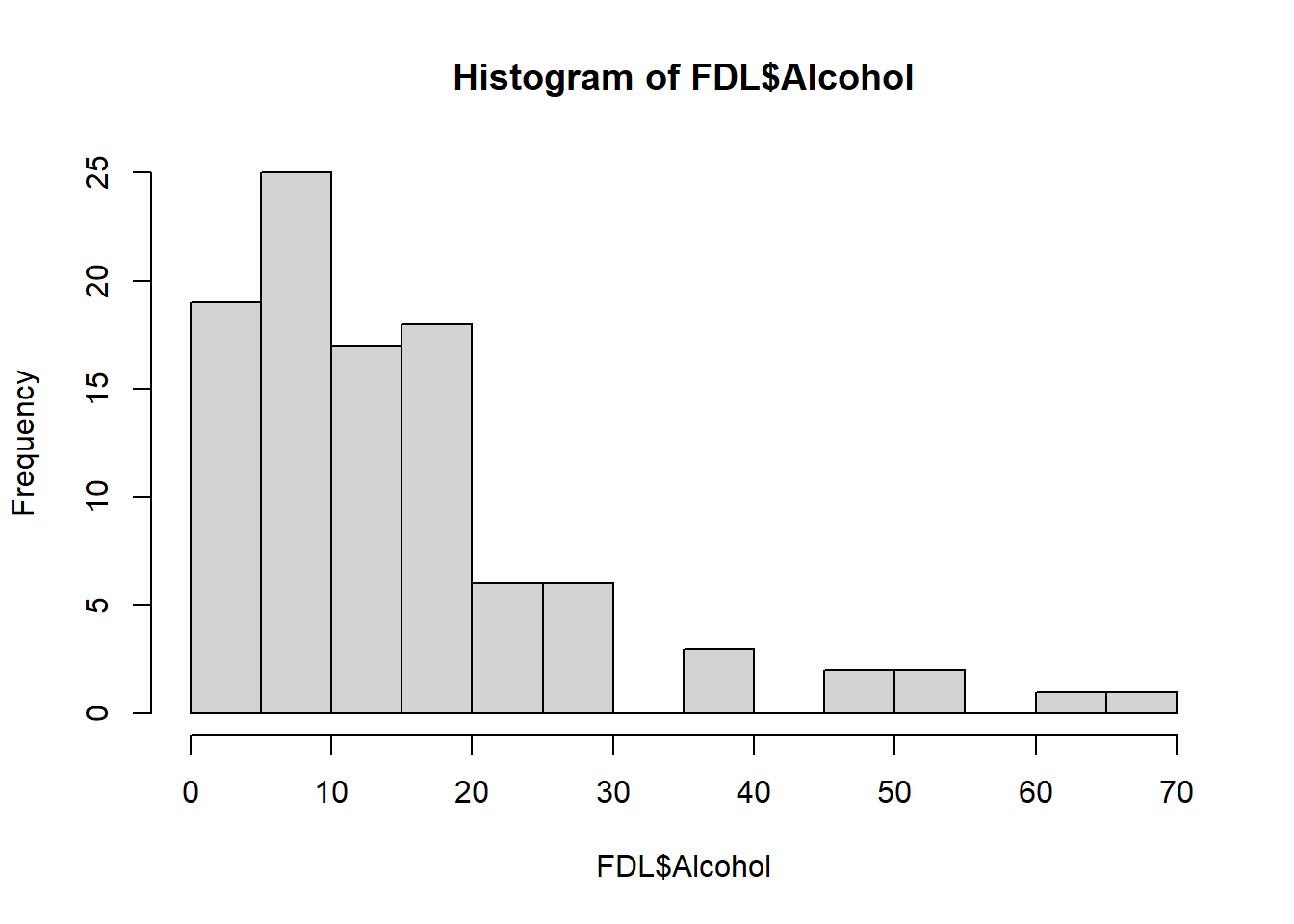
Als we de correlatie tussen We krijgen een melding “Cannot compute exact p-value with ties”. Deze melding kunnen we negeren, er wordt voor ons blijkbaar geen exacte p-waarde berekend, maar een benadering ervan. We vinden een redelijk (‘medium’) verband tussen alcoholgebruik en de voormeting van de FDL (\(\rho\) = 0.38), welke statistisch significant is (p < .001). |
|
We hebben hierboven wat basale statistische tests besproken. Er zijn natuurlijk veel meer statistische tests beschikbaar. Denk aan nonparametrische alternatieven voor de t-toetsen hierboven, anova’s, regressie-analyses, enzovoorts. Je favoriete zoekmachine helpt je hier graag bij. Ook een aanrader is het boek van Field, Miles en Field (2012). |
|
Om je een beeld te geven van hoe een volledig script er uit zou kunnen zien, geven we je hieronder een voorbeeld. |
|
In deze tutorial heb je wat basale vaardigheden in R geleerd. Als je meer wilt weten: Google is your friend! Als je ergens tegenaan loopt, iets wilt in R maar je weet niet hoe: je bent hoogstwaarschijnlijk niet de eerste. Verder heb je bijvoorbeeld:
|