Hoe zet ik een SPSS-databestand op?
Mathijs Deen, statisticus/methodoloog
In deze tutorial leer je hoe je eenvoudig een SPSS-databestand kunt opzetten. Als je de tutorial hebt doorlopen, kun je niet alleen een SPSS-bestand maken dat gereed is voor invoer, je hebt ook geleerd eenvoudige bewerkingen uit te voeren om van je ruwe invoer tot bruikbare uitkomstmaten te komen.
Een leeg bestand.
Als je SPSS voor de eerste keer opstart, krijg je het volgende scherm te zien:
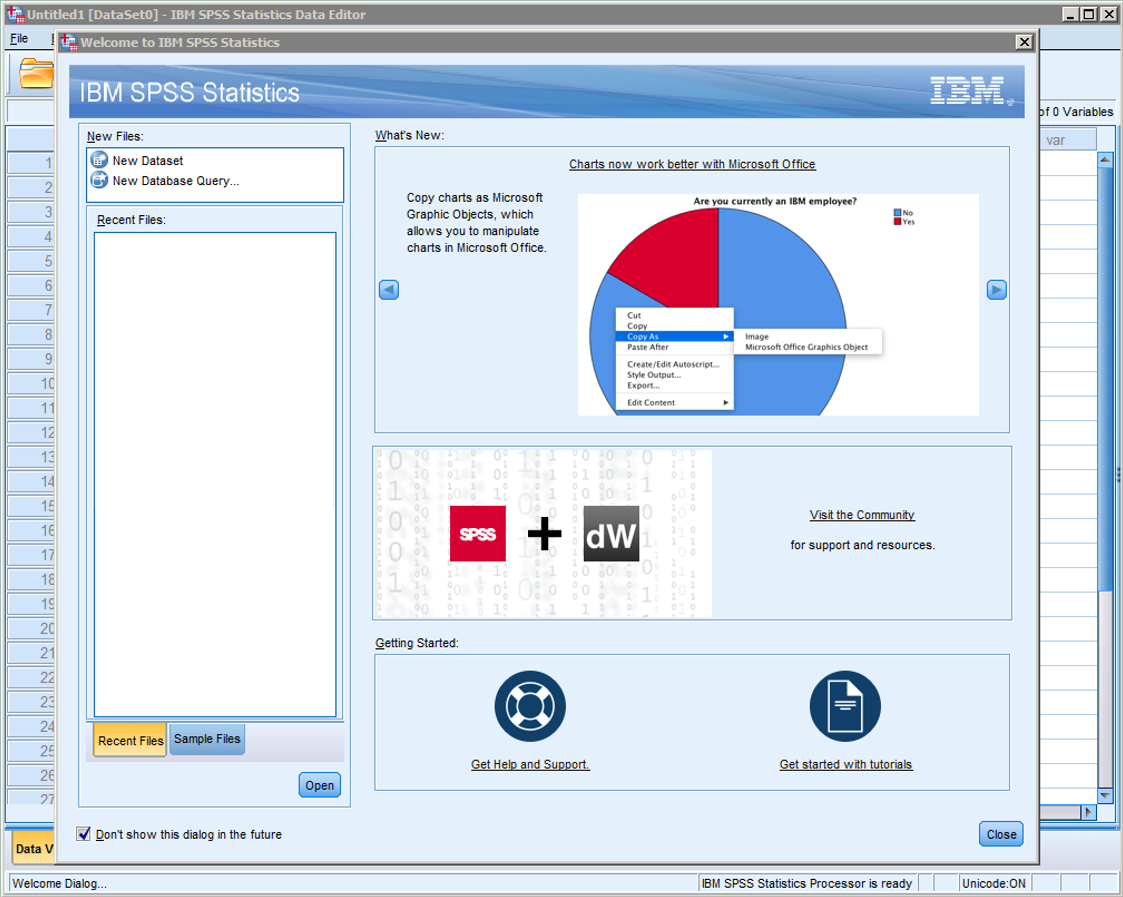
Het is aan te raden om linksonderaan “Don’t show this dialog in the future” aan te vinken. Het opstarten van SPSS duurt, zoals je misschien merkte, al lang genoeg… We kiezen voor “New Dataset” en klikken op “Close”. Het scherm dat je hierna ziet, zal er ongeveer zo uit zien:
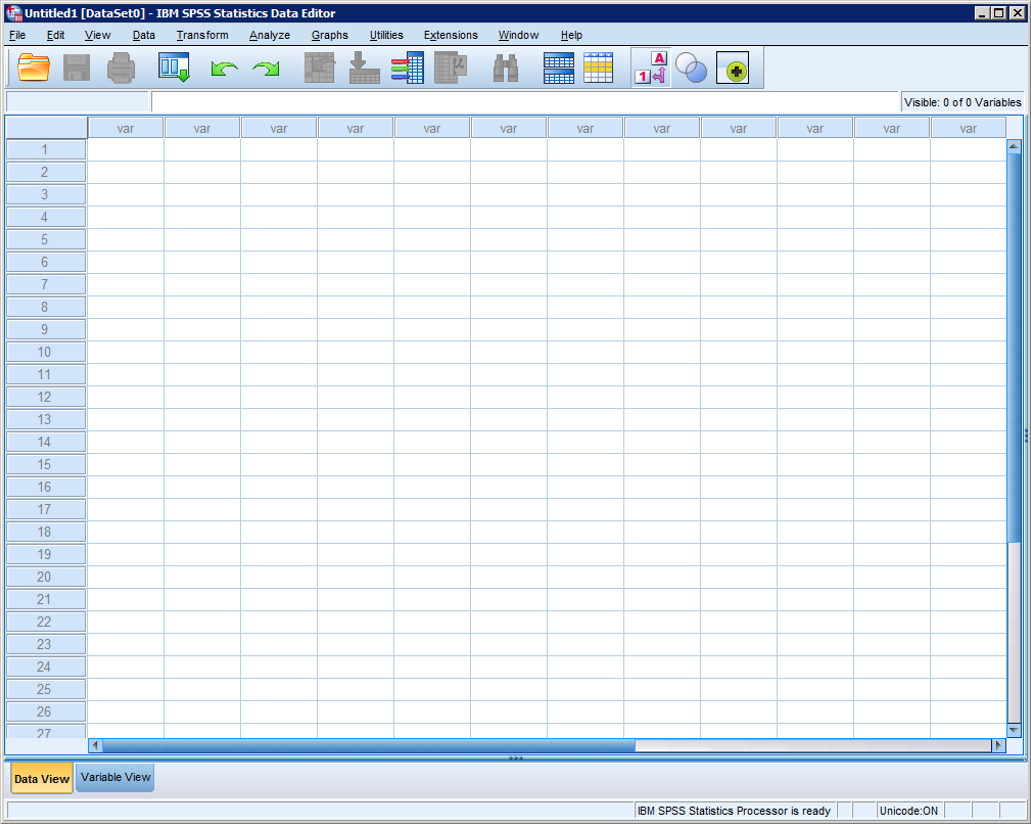
We zien lege cellen, daarboven een knoppenbalk en een menustructuur, en onderaan het scherm valt te zien dat er twee tabbladen zijn: “Data View” en “Variable View”. In Variable View zien we de eigenschappen van variabelen, waarvan we in Data View de ruwe data zien. Als we een nieuwe variabele aanmaken in Variable View, kunnen we deze bepaalde eigenschappen geven (waarover straks meer), vervolgens kunnen we onder Data View daadwerkelijk data invoeren.
Opdracht: Ga naar het tabblad Variable View, klik op de de cel onder “Name”, op de eerste rij, typ daar “ID” en sluit af met enter.
Je hebt zojuist de variabele “ID” aangemaakt. Het is gebruikelijk om als eerste variabele in je dataset een variabele te hebben die personen (of, strikter: observaties) van elkaar te onderscheiden. Een zgn. proefpersoonnummer. Je ziet dat SPSS een aantal eigenschappen voor de variabele invulde, toen je op enter drukte. De belangrijkste eigenschappen naast de variabelenaam zijn: Type, Decimals, Label, Values, Missing en Measure. We lopen deze even langs, verderop volgt een uitleg:
- Name: de naam van je variabele. Let op: deze mag geen spaties of leestekens bevatten (een underscore mag wel).
- Type: het type variabele. Veelgebruikte types zijn:
- Numeric, voor getallen.
- Date, voor datumvariabelen.
- String, voor tekst.
- Decimals: het aantal decimalen van je numerieke variabele.
- Label: hier kun je een korte omschrijving van je variabele neerzetten.
- Values: je kunt verschillende getallen een waarde toewijzen.
- Missing: verschillende soorten missende waarden zijn te definiëren.
- Measure: hier kies je het meetniveau van je variabele. SPSS hanteert de volgende meetniveaus:
- Nominal, voor nominale variabelen (denk aan geslacht, etniciteit, diagnose).
- Ordinal, voor ordinale variabelen (denk aan opleiding, sociaaleconomische status, items van een vragenlijst met bijv. een vijfpuntsschaal).
- Scale, voor variabelen van interval- en rationiveau (denk aan leeftijd, totaalscore op een vragenlijst, lichaamsgewicht).
Voor de variabele ID van zojuist geldt dat dit een numerieke variabele is. Het aantal decimalen kunnen we op 0 zetten. Dit doen we door de 2 in de kolom Decimals te veranderen. Als label kunnen we deze variabele bijvoorbeeld “Proefpersoonnummer” geven. In dit geval hoeven we geen values in te vullen, en geen missings. Het meetniveau is nominaal. Nu zie je bij Measure nog “Unknown” staan, dit kun je wijzigen door er op te klikken.
De data in je databestand
Voor we verdergaan met de opbouw, staan we eerst even stil bij wat er nou eigenlijk in je databestand komt te staan. Zo voer je geen onnodige data in, en vergeet je geen relevante data in te voeren.
Je gebruikt je databestand natuurlijk om data te analyseren. Wat je gaat analyseren, is afhankelijk van je onderzoeksvraag/-vragen. Het is gebruikelijk om aan de hand van je onderzoeksvraag te bepalen welke uitkomstmaten je hebt. Het kan zijn dat je de onderzoeksdeelnemer vragenlijsten laat invullen, dat je fysiologische eigenschappen bepaalt (lengte, gewicht, bloedspiegels, etc.), of dat je demografische kenmerken verzamelt. Een combinatie kan natuurlijk ook.
Sommige van de benodigde gegevens zijn eenvoudig in je dataset te krijgen. Voor lichaamsgewicht bijvoorbeeld, is het een kwestie van kijken wat de weegschaal aangeeft, en zorgen dat die informatie in de variabele “Gewicht” komt te staan. Voor andere variabelen is het wat meer werk. Stel, je wilt de schaal Psychoneuroticisme van de SCL-90 gebruiken, dan moet je eerst de 90 items van de SCL-90 invoeren, om vervolgens deze items om te zetten in een totaalscore. Je kunt voor het bepalen van de benodigde gegevens achterwaarts denken, in twee stappen:
- Welke variabelen heb ik nodig om mijn onderzoeksvraag te beantwoorden?
- Hoe komen die benodigde variabelen tot stand? Voor de genoemde voorbeelden: het aflezen van een weegschaal, en het laten invullen van de SCL-90, items invoeren en totaalscore berekenen.
Het lijkt wat overdreven dat ik dit hier zo expliciet benoem, maar ik kom nog vaak onderzoekers tegen die veel meer informatie verzamelen dan ze uiteindelijk nodig hebben voor het beantwoorden van hun onderzoeksvraag. Niet alleen doe je dan onnodig werk, het is ook nog eens onethisch om onze patiënten onnodig te belasten met dataverzameling.
Een gangbare opbouw van je databestand
De eerste variabele, ID, heb je al ingevuld. Zoals eerder gezegd, dit is gewoonlijk de eerste variabele in je dataset. Wat gebruikelijk is, is om eerst wat benodigde demografische kenmerken aan te maken. Deze staan meestal bovenin (of voorin, zo je wilt) het databestand. Daarna volgen gewoonlijk eventuele fysiologische eigenschappen en/of de data van vragenlijsten.
De opties Values en Missing: demografische variabelen
Stel, je wilt een variabele aanmaken voor het geslacht van de proefdeelnemers. In het tabblad Variable View kun je dit in de tweede rij doen.
Opdracht: ga in de tweede rij in de kolom Name staan, typ daar “Geslacht” en druk op enter. Zorg dat het aantal decimalen op 0 komt te staan, geef deze variabele het label “Geslacht van de participant”, en maak dat deze variabele qua meetniveau als nominaal wordt gezien. De variabele is van het numerieke type.
We willen nu voor deze variabele definiëren welk getal we de mannen geven, en welk getal we de vrouwen geven. Dit doen we door “Values” in te stellen. We gaan de mannen het getal 0 geven, vrouwen het getal 1.
Opdracht: klik voor de variabele Geslacht op “None” in de kolom Values. Als er niet meteen een nieuw schermpje tevoorschijn komt, moet je op het kleine knopje met de drie puntjes (rechts van “None”) klikken. Voer bij Value in: 0, en bij Label: man. Klik op Add om dit te voltooien. Geef op dezelfde wijze de waarde “1” aan “vrouw”. Als ze allebei in het lijstje staan, klik je op OK.
Je hebt zojuist de variabele Geslacht aangemaakt.
Opdracht: maak een variabele “Opleidingsniveau” aan, met als label “Opleidingsniveau”. Dit is een numerieke variabele van ordinaal meetniveau, met 0 decimalen, en met als values 0, 1 en 2 voor respectievelijk laag, midden en hoog.
Je bepaalt zelf welk nummer een proefpersoon bij de variabele “ID” krijgt. Het geslacht kun je doorgaans ook wel bepalen. Op deze twee variabelen zul je waarschijnlijk geen missende waarden hebben. Voor opleidingsniveau zou dit echter zomaar kunnen gebeuren: het kan zomaar zijn dat iemand dit niet heeft ingevuld. Je kunt ervoor kiezen om in SPSS missende waarden te definiëren. Een veel gehanteerde waarde is 999. Let wel: gebruik deze waarde alleen als het geen reële waarde is. Stel dat je een variabele “Inkomen” hebt, dan kan het zomaar zijn dat iemand écht precies 999 euro verdient. Die wil je niet onterecht als missing laten gelden. Je kunt er dan voor kiezen om bijvoorbeeld de waarde “-1” te nemen.
Opdracht: Klik op de regel voor “Opleidingsniveau” op “None” in de kolom Missings. Vink de keuze “Discrete missing values” aan, en zet in het linker vakje de waarde 999.
Je ziet drie vakjes staan. Dit is, omdat er meerdere soorten missings zijn. Stel dat je een vragenlijst hebt, waarbij sommige vragen niet hoeven te worden ingevuld, afhankelijk van wat er bij een andere vraag wordt ingevuld (“indien nee, sla de volgende vraag over”). Dan kan het zijn dat iemand de vervolgvraag niet had hoeven invullen, of dat iemand de vraag wel had moeten invullen, maar dat dus niet gedaan heeft. Zie het als een geoorloofde en een ongeoorloofde missing. Deze wil je wellicht van elkaar onderscheiden, en hier kun je verschillende soorten missings voor gebruiken. Gebruikelijk is om voor zo’n geoorloofde missing de waarde 888 te hanteren, dit vul je dan in het tweede vakje in. Klik op OK om de wijzigingen m.b.t. missing values op te slaan.
Let op: het is lang niet altijd noodzakelijk om missing values te definiëren. Als je meerdere soorten missings hebt, dan is het handig, maar als je alleen maar missings hebt die ik hierboven “ongeoorloofd” noemde, kun je de cel met de betreffende missende waarde ook gewoon leeg laten. Scheelt je het onnodig definiëren van missings, bovendien gaat het regelmatig fout: onderzoekers die wél de waarde 999 invullen, maar deze niet in de kolom Missing hebben gedefinieerd. Deze waarden worden dan niet als missend behandeld. Je krijgt dan gekke vertekeningen in je data: mensen die 999 cm lang zijn, 999 kilo wegen, een score van 999 op de SCL-90 krijgen, etc… Mijn advies: heb je maar 1 soort missings, laat de cel dan leeg en de waarde 999 achterwege.
Opdracht: maak onze tutorialdataset af door een variabele voor gewicht (naam “Gewicht”), lichaamslengte (“Lengte”), BMI (“BMI”)) en vijf vragen uit een fictieve vragenlijst (“Q1” t/m “Q5”) aan te maken. De vijf vragen hebben vijf oplopende antwoordcategorieën “Helemaal mee oneens”, “Mee oneens”, “Neutraal”, “Mee eens” en “Helemaal mee eens”, met als respectievelijke waarden 1, 2, 3, 4 en 5. (Tip: maak deze values voor Q1 aan, en copypaste ze naar Q2 t/m Q5). Denk zelf na over aantal decimalen, meetniveau, label en type.
Als je dit gedaan hebt, zou je Variable View er zo uit kunnen zien:
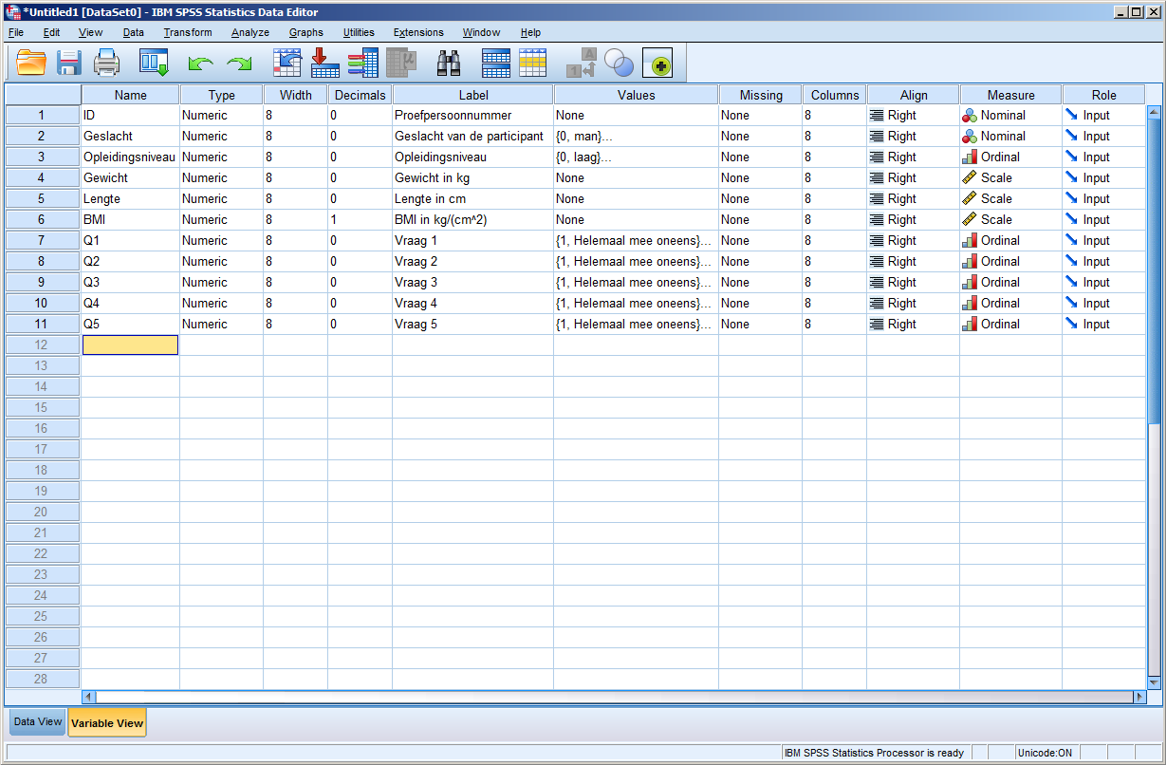
Voor de items van een vragenlijst is het gangbaar om de naam te laten beginnen met de naam van de vragenlijst, gevolgd door het itemnummer binnen die vragenlijst. Zo zie je vaak variabelenamen als “SCL90_01” t/m “SCL90_90”, “SIPP118_001” t/m “SIPP118_118” etc. Als je herhaalde metingen hebt, wordt daar nog een conventie aan toegevoegd, zie daarvoor verderop onder het kopje “Handig om te weten”.
Data invoeren
Tot nu toe hebben we alleen nog maar in het tabblad Variable View gewerkt. Als we data willen invoeren, doen we dit in het tabblad Data View. Voor ons voorbeeld maken we een heel kleine dataset van zes mensen.
Opdracht: ga naar het tabblad Data View en voer de data inzoals hieronder weergegeven. Met de knop  kun je schakelen tussen het weergeven van de labels en de waarden, zoals je ze in de kolom Values eventueel hebt gedefinieerd. Zorg er voor dat deze knop nu niet ingedrukt staat, je ziet dan de waarden, niet de labels.
kun je schakelen tussen het weergeven van de labels en de waarden, zoals je ze in de kolom Values eventueel hebt gedefinieerd. Zorg er voor dat deze knop nu niet ingedrukt staat, je ziet dan de waarden, niet de labels.

Berekeningen? Laat SPSS het werk voor je doen
Zoals je ziet, hebben we BMI nog niet ingevuld. Dit kun je natuurlijk voor iedere proefpersoon met de hand gaan uitrekenen, maar we kunnen dit beter door SPSS laten doen.
Opdracht: ga in het menu naar Transform, en dan naar Compute Variable. Vul bij Target Variable in: BMI. Typ bij Numeric Expression: Gewicht/( (Lengte/100) **2). In plaats van de variabelenamen in te typen, kun je ze ook uit het lijstje in het tekstvak slepen. Als je op OK klikt, krijg je de vraag of je de bestaande variabele wilt wijzigen. Deze melding krijg je omdat de variabele al bestaat. Als je op OK klikt, wordt de huidige variabele overschreven. Maakt voor nu niet uit, er stond toch nog niets in.
Je herkent misschien de BMI-formule: het gewicht wordt gedeeld door het kwadraat van de lengte in meters (let op het delen door 100!).
Opdracht: We willen ook nog een totaalscore voor onze vijf vragen berekenen. Vul in het menu Compute Variable de vakjes als volgt in, en klik op enter:
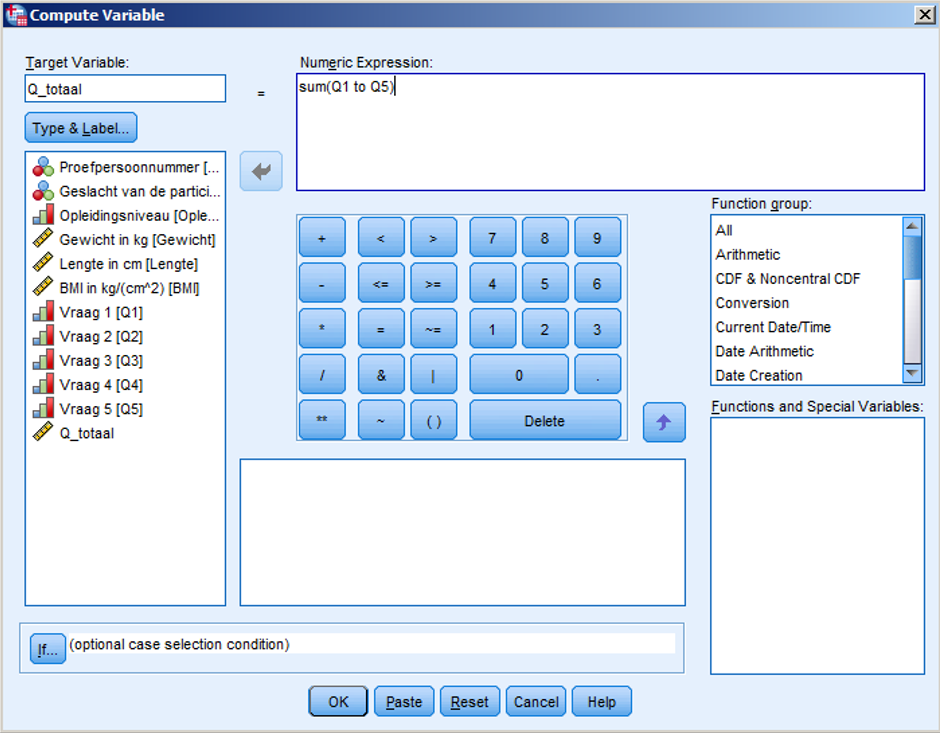
Je ziet dat de variabele “Q_totaal” voor je is berekend.
Opdracht: maak de variabele Q_totaal2 aan, door in Numeric Expression in te vullen: Q1 + Q2 + Q3 + Q4 + Q5. Vergeet niet de naam van de Target Variable te veranderen in “Q_totaal2”! Wat is het verschil in uitkomst met de eerdere methode voor “Q_totaal”? Wat zijn de voordelen en gevaren van het gebruiken van de eerste en de tweede methode? Hoe kun je dit oplossen?
Handig om te weten
Herhaalde metingen
Soms maak je gebruik van herhaalde metingen. Stel, je neemt onze fictieve vragenlijst drie keer af: een keer voorafgaand aan een behandeling, een keer bij de afronding ervan, en nog een keer drie maanden daarna (een zgn. follow-up). Je kunt hier op twee manieren mee omgaan: je kunt de items drie keer aanmaken, zo krijg je dus 15 variabelen. Wat je veel ziet, is dat dan voor de eerste meting de items de namen “Q1_M1” t/m “Q5_M1” krijgen, voor de tweede meting “Q1_M2” t/m “Q5_M2” en voor de derde meting “Q1_M3” t/m “Q5_M3”. Dit wordt in het Engels een “wide format” genoemd.
Je kunt ook elke proefpersoon drie rijen in je databestand geven en een extra variabele “Metingnummer” aanmaken, welke binnen elke proefpersoon de waarden 0, 1 en 2 krijgt voor de voor- na- en followupmetingen. Je hebt dan minder variabelen, maar meer rijen. Zo hou je je dataset wat overzichtelijker. Dit wordt het “long format” genoemd. Welke optie je kiest, is echter ook afhankelijk van de uiteindelijke statistische toets die je wilt uitvoeren. Overleg evt. met je statisticus wat voor jou de beste optie is.
Omscoren / ompolen / spiegelen
Soms worden vragen gespiegeld gesteld. Stel dat je een vragenlijst hebt waarbij de items doorgaans van het type “hoe hoger, des te slechter” zijn, maar er zit een paar items in waarbij dat net andersom is (dus: hoe hoger, des te beter). Dan moeten er dus items gespiegeld worden. Dit kun je doen via Recode into Different Variables in het menu Transform. Er is ook Recode into Same Variables, maar ik raad je af om die ooit te gebruiken. Bij dit hercoderen maak je een nieuwe variabele aan, waarin je voor elk van de waarden van je huidige (nog ongespiegelde) variabele, de nieuwe waarde kunt opgeven. Voor de naam van de nieuwe variabele is het handig om de naam van je originele variabele te gebruiken, met bijv. de toevoeging “_R” (de R van “Reverse”). Zo zou je in onze fictieve vragenlijst kunnen zien dat de variabele “Q4_R” een gespiegelde versie is van “Q4”. Raadpleeg altijd de handleiding of scoringsinstructie van je vragenlijst om meer te weten te komen over het eventuele omscoren van items.
Data uit externe digitale bronnen
Als je data aangeleverd krijgt uit externe digitale bronnen, hoef je deze niet zelf in te voeren. Ga vooraf na hoe de dataset die je aangeleverd krijgt, eruit ziet. Het kan zijn dat je een bestand krijgt wat uit een omgeving voor digitale afname wordt geëxporteerd, waar alle variabelen al netjes in gedefinieerd zijn, en je hele dataset dus eigenlijk al gereed is. Dan is het uiteraard niet noodzakelijk zelf een complete dataset op te bouwen.